Member-only story
2 min readMar 1, 2025
How to Effortlessly Flatten Any JSON in PySpark — No More Nested Headaches!
Recently, while working on the project, I got a chance to work on the use case for flattening n-level JSON data.
The approach that I followed helped me to flatten data at any level with complex structure.
Let’s walk through the code step by step and understand the logic:
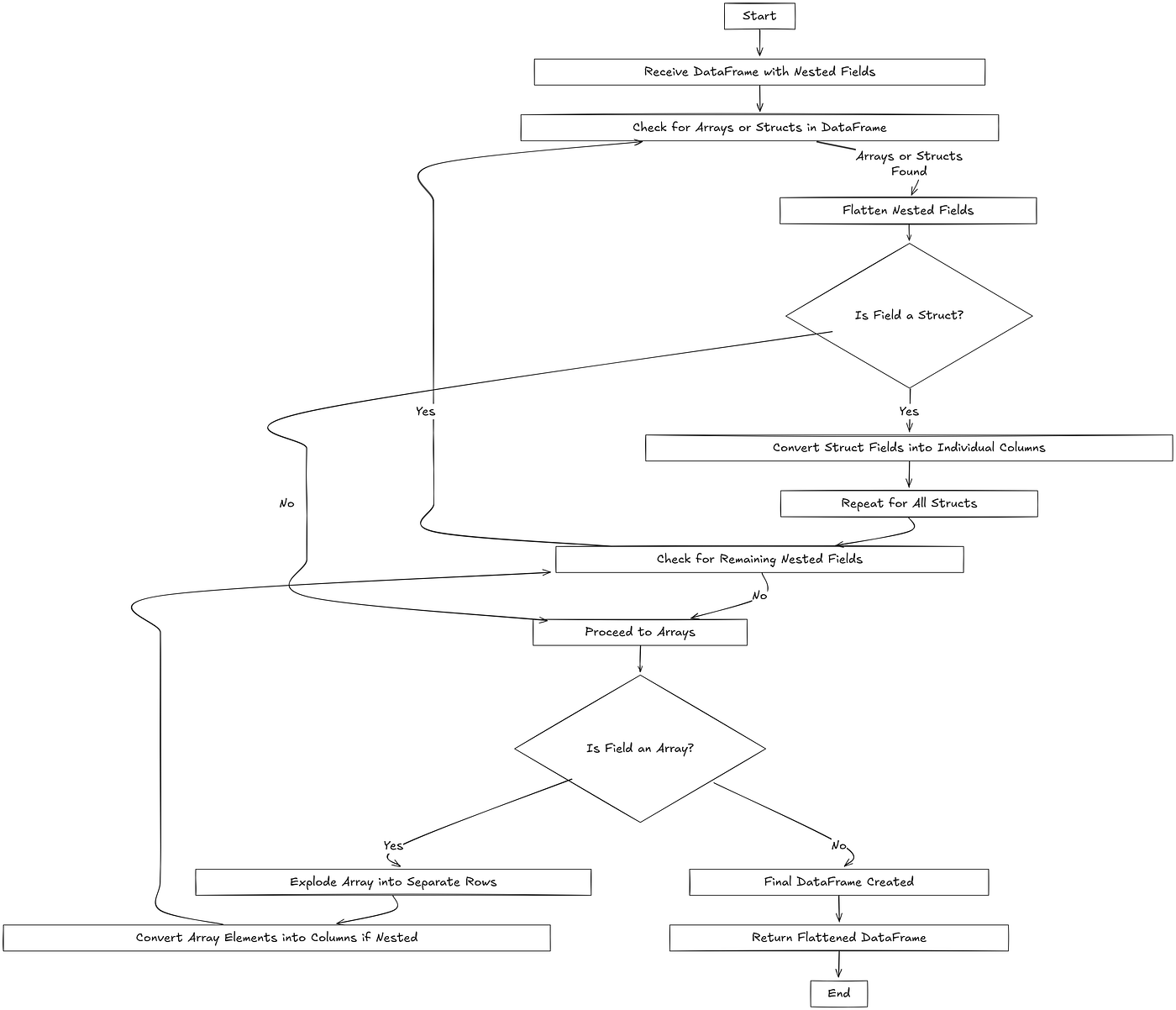
- Recursively flattens a DataFrame with complex nested fields (Arrays and Structs) by converting them into individual columns.
2. Parameters: df (DataFrame): The input DataFrame with complex nested fields.
3. Returns:DataFrame: The flattened DataFrame with all complex fields expanded into separate columns.
from pyspark.sql.functions import col, explode_outer
from pyspark.sql.types import StructType, ArrayType
def flatten_json(df):
def get_complex_fields(df):
# Returns a dictionary of complex (Array or Struct) fields in the DataFrame schema.
return {field.name: field.dataType for field in df.schema.fields if isinstance(field.dataType, (ArrayType, StructType))}
#Retrieves all Structs & Arrays in the DataFrame.
#If no complex fields exist, the function simply returns the original DataFrame.
complex_fields = get_complex_fields(df)
while complex_fields:
col_name, col_type =…