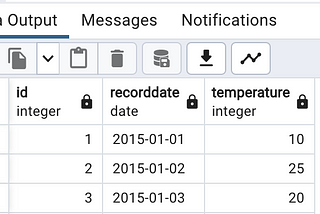
PinnedExploring PySpark Setup in Visual Studio CodeThis article provides a step-by-step guide to setting up your environment, leveraging the robust capabilities of PySpark, and seamlessly…Dec 16, 20231Dec 16, 20231
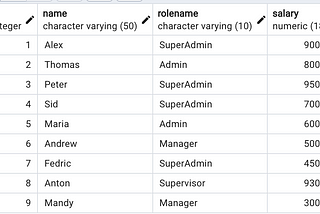
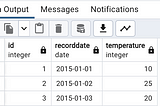
PinnedSQL Interview QuestionsIn this article, I will be sharing a few SQL interview questions which are commonly asked in SQL interviews.Mar 18, 20234Mar 18, 20234
PinnedAzure Data Engineering Interview QuestionsData engineering plays a critical role in the world of data science and analytics.Jul 29, 20231Jul 29, 20231
PinnedFrom Preparation to Success: A Roadmap for Passing Databricks Certified Data Engineering AssociateHello!! My medium family this time I am back with an article, sharing my journey from preparation to success for the certificate exam.Oct 14, 2023Oct 14, 2023
PinnedAzure Synapse vs Databricks: Choosing the Right Big Data PlatformIn the rapidly evolving landscape of big data analytics, organizations are faced with the challenge of selecting the right platform that…Jan 31, 20246Jan 31, 20246
Cluster Access Mode in DatabricksRecently, while working on an AutoML use case in our current project, we encountered a situation where the entire team needed to…4h ago4h ago
Published inCode Like A GirlFrom Preparation to Success: A Roadmap for Passing Microsoft Certified: Microsoft Fabric Data…Hello!! My medium family, this time I am back with another article, sharing my journey from preparation to success for the certificate…Mar 29Mar 29
How to Effortlessly Flatten Any JSON in PySpark — No More Nested Headaches!Recently, while working on the project, I got a chance to work on the use case for flattening n-level JSON data.Mar 1Mar 1
Real-Time Data Sharing in Databricks: Streaming Data with Delta SharingDelta Sharing is an open protocol for securely sharing live data across organizations, regardless of the computing platforms they use…Mar 1Mar 1
Implementing Unity Catalog with Medallion Architecture: A Mini ProjectProject Description: Enable a Databricks workspace with Unity Catalog for centralized data governance and access control. Implement a…Feb 16Feb 16